本文是对Real-Time Rendering一书中第18章Graphics Hardware的读书笔记。
Chapter 18 - Graphics Hardware
尽管图形硬件变化很快,但还是有一些通用的概念架构设计。
18.1 缓存(Buffers and Buffering)
帧缓存的内存可能存在于和CPU同样的内存空间中(某个专用的帧缓存内存空间),也可能存在于显存(video memory)中。显存中包含了所有的GPU数据,但不能直接被CPU访问。颜色缓存(color buffer)是帧缓存(frame buffer)的一部分。它通过某种方式和一个显示控制器(video controllder)相连,显示控制器又和某个显示器相连。如下图所示。显示控制器通常包含了一个数字模拟转换器(digital-to-analog converter,DAC),数字模拟转换器负责把数字像素值转换成一个模拟信号进行显示。由于DAC需要在每一帧时对所有像素都进行转换,因此系统必须拥有很高的带宽(bandwidth)。基于CRT的设备是模拟设备(analog devices),因此它需要接受模拟输入(意味着之前需要把数字信息转换成模拟信号再传递给它进行显示)。而基于LCD的显示设备是数字设备(digital devices),但它们通常既可以接受模拟输入也可以接受数字输入。我们的个人电脑使用的是数字视频接口(digital visual interface,DVI),也被称为显示端口接口(Display Port digital interfaces),而诸如游戏系统和电视机这样的电子设备则通常使用的是高清晰度多媒体接口(high-definition multimedia interface,HDMI)。
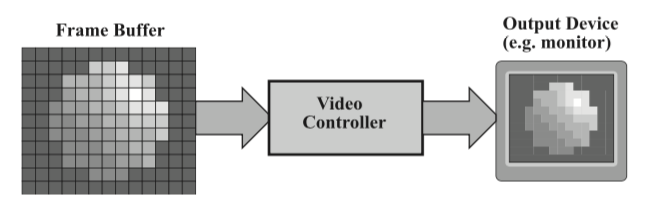 图示:一个简单的显示系统:显示控制器负责扫描颜色缓存,得到每个像素的颜色值后将其用于控制输出设备的显示强度。
图示:一个简单的显示系统:显示控制器负责扫描颜色缓存,得到每个像素的颜色值后将其用于控制输出设备的显示强度。
阴极射线管(CRT)显示器刷新图像的速率通常在60到120Hz/s。显示控制器的任务就是扫描整个颜色缓存,一条扫描线接着一条扫描线。显示控制器是和显示器的电子束(beam)同步工作的,也就是说它们的扫描速率是一致的(可以这样理解,显示器的电子束扫描到哪里,就会把显示屏的该区域点亮,与此同时显示控制器也按照同样的速率读取颜色缓存,并将其作为输入提供给显示器的电子束来控制显示器的显示亮度,因此两者扫描速率是同步的)。需要注意的是,电子束的移动轨迹通常是从左到右、从上到下的。因此,当电子束扫描完一行需要重新从右边移到左边扫描下一行时,这个从右移到左的过程是不会对屏幕图像产生任何影响的。这被称为水平回扫(horizontal retrace)。与之相关的还有水平刷新率(horizontal refresh rate),这个值就是指完成一次完整的左-右-左过程所需要的时间。而垂直回扫(vertical retrace)就是指电子束从右下移动到左上开始扫描下一帧的过程,同样,垂直刷新率(vertical refresh rate)就是每秒完成这个过程的次数。当它小于72Hz时,大多数用户就会察觉到画面跳帧了。这个过程如下图所示。
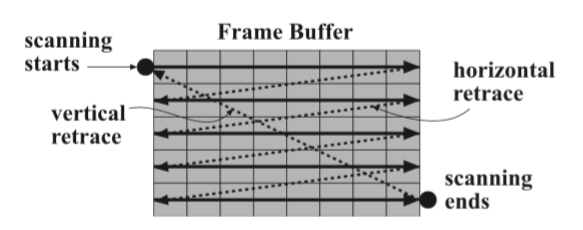 图示:显示器的水平和垂直回扫。这里显示的颜色缓存有5行。扫描线开始于左上角,然后每次会扫描一行。当扫描到一行的结尾时,它需要移动到下一行的开头。这个过程就是水平回扫。当扫描到最后的右下角时,本次扫描就结束了,就需要再移动到左上角来进行下一帧的扫描。这个移动过程被称为垂直回扫。
图示:显示器的水平和垂直回扫。这里显示的颜色缓存有5行。扫描线开始于左上角,然后每次会扫描一行。当扫描到一行的结尾时,它需要移动到下一行的开头。这个过程就是水平回扫。当扫描到最后的右下角时,本次扫描就结束了,就需要再移动到左上角来进行下一帧的扫描。这个移动过程被称为垂直回扫。
液晶显示器( liquid crystal display,LCD)通常的刷新率为60Hz。而CRT需要更高的刷新率(60到120Hz)是因为当电子束移开后显示器上的磷光剂就开始逐渐变暗了(因此如果不快点的话之前扫过的就都变得很暗了)。而LCD可以持续传输光,因此不需要很高的刷新率。而且LCD也不需要回扫时间。但LCD同样有垂直同步的概念,这里的刷新率会受当前生成哪些帧的影响(笔者注:实际上应该是指液晶的响应时间)。
笔者注:这里再补充说明下CRT和LCD显示设备的区别。 CRT的成像原理简单来说就是靠电子束逐行扫描屏幕,屏幕上的磷光剂受到电子轰击后就会短暂亮起,然后逐渐变暗。因此,如果显示器的刷新频率太低,就会造成屏幕黑屏。所以严格来说,CRT显示设备总是处于变亮-变暗-变亮的循环过程,这种一定速率黑屏并不一定是坏事,例如如果总是保持点亮状态,由于人眼的特性会自动对亮部状态做积分,因此对于运动画面会自动进行平滑处理,使得有时运动画面过于模糊。这正是LCD显示设备。LCD显示设备是没有变暗这一概念的。它的成像原理是向液晶通电时,液晶分子排列可以使得光线容易通过,而不通电时则分子排列混乱组织光线通过,而这些光线是由显示器的背光管提供的,背光管是持续保持发光状态的。也就是说,当没有显示信号时,LCD显示设备将总是保持当前的画面,并不会发生黑屏现象。尽管LCD设备不需要逐行扫描,可以做到快速全屏更新,但为了兼容CRT设备的工作原理,它也仍然配合视频控制器来进行逐行更新,但显然它不需要回扫时间。但是,LCD设备的显示质量(即刷新率)会受响应时间的影响。响应时间大致指的是液晶分子对电压的响应能力,当响应时间大于帧画面的更新时间时,显示器就会出现拖尾现象,这是因为液晶分子无法跟上画面的更新速度。 参考:http://sssa2000.github.io/blog/2014/05/19/lcd/, http://tieba.baidu.com/p/1535590985
与该话题相关的是隔行扫描(interlacing)。计算机显示器通常不是隔行扫描的,而是逐行扫描(progressive scan)的。而电视机则是隔行扫描的,也就是说,在一次垂直刷新过程中,奇数行会被绘制,然后在下一个刷新过程中,偶数行会被绘制。
笔者注:我们很容易联想到垂直同步的事情,这里也补充说明下。 提到垂直同步,不得不提到画面撕裂,这是提出垂直同步的动机。如下图所示,画面撕裂其实就是显示器在显示画面时读取了多个帧画面。这是因为,显示器和帧缓存个更新其实是异步的,当视频控制器还在扫描当前帧缓存中的像素时,显卡已经完成了新一帧的绘制并更新了帧缓存,导致视频控制器对于到了不同帧的颜色数据。也就是说,当GPU的帧渲染速率大于显示设备的刷新率时,就有可能会出现画面撕裂。当然,如果当渲染速率远大于刷新率时撕裂可能也不会非常明显,因为刷新屏幕时使用了多个帧画面使得每个撕裂条都不是那么明显。 我们已经知道了画面撕裂是由于显卡和显示器之间的异步造成,那么解决方法就是同步它们,也就是多重缓存和垂直同步。当开启了垂直同步后,只有在显示器完成了当前的刷新工作后,显卡才能进行任何对显示缓存的显示工作。具体来说,在显示设备每次垂直回扫(也被称为VBlank)时,才可以被允许快速更换双缓冲之间的内容(假定使用的是双缓存技术)或是在两者之间完成一次交换(假定使用的是页面翻转的功能)。这样就可以保证显示器在刷新时总是读取到同一个帧缓存中的数据。需要注意的是,垂直同步只是阻塞了显卡的present方法。 然而,开启垂直同步虽然可以解决画面撕裂的问题但也引入了新的问题。最大的问题就是帧率下降的问题。由于开启垂直同步后,渲染的实际更新速率将受显示设备刷新速率的限制,也就是说如果一个显示设备的刷新率为60帧,那么渲染的更新速率也不会超过60帧。关键是,这个渲染速率可能会远小于显示设备的更新速率,造成画面卡顿。出现这种现象的原因是,我们的显卡常常会miss掉垂直同步的机会,造成总是无法及时更新画面。在这篇文章里,作者把这个过程比喻成搭乘地铁。“一般来说,地铁到达每一站的时间均是平均且一定的,假设每10分钟一班接走一批乘客。但是几乎没有多少乘客可以按点到达,如果提前两分钟到达,则只需要等待两分钟即可乘上地铁,但是,如果你错过了,哪怕只差了一分钟,那么你也不得不再等待九分钟才能乘上地铁。”对应到这里,地铁到站相当于垂直回扫的时间到了,我们需要交换双缓存里的内容来进行画面更新,但此时乘客还没有到(渲染还没有完成),那么本次渲染就错过了更新时机,只能等待下一次地铁到站了。这样的情况多了,就会造成帧率大幅下降,尤其是本来渲染速率就小于显示设备的刷新速率时还要等待这就很捉急了。 Nvidia提出了一种自适应同步(Adaptive Vsync)的方法,当渲染引擎的渲染速率大于显示设备的刷新速率时就自动开启垂直同步,否则就关闭。 参考: http://sssa2000.github.io/blog/2014/03/19/vsync-1/

18.1.1 颜色缓存
讲到了颜色缓存中的存储模式:
- 高彩(Hight color):每个像素占两个bytes,即每个颜色使用15或16个bits,可以表示32768或65536种颜色。
- 真彩或RGB颜色:每个像素占3个或4个bytes,即每个颜色使用24个bits,可以表示16777216种颜色。
高彩模式中,RGB通道各有至少5个bits,可以表示32个层阶。这样就还剩下1个bit(16-3*5),这个bit通常会留给G通道,得到一个5-6-5的分配结果。之所以选择绿色通道是因为它的亮度值对人眼的影响最大,因此需要更多的精度。
高彩模式相对于真彩具有更高的速度优势。即便如此,高彩模式逐渐退出了PC显卡的舞台。然而,一些笔记本则使用18 bits来存储颜色,例如每个通道使用6个bits。而移动设备则通常使用16或18 bits,但它们也支持使用24 bits。
由于这种模式只有32个或64个色阶,我们是可以看到相邻色阶之间明显的边界。而人眼的特性会进一步加强这种边界差异,这种视觉现象被称为马赫带(Mach banding)效果。
而真彩则使用24个bits来表示,每个通道有8个bits。在内部实现上,这些颜色可能会被存储为24或32 bits。之所以可能会选择32 bits是因为这种格式下数据访问更快。在一些系统里,多出来的这8个bits会用于存储透明通道,得到一个RGBA值。这种24-bit的颜色表示被称为压缩像素格式(packed pixel format),因为相比于32-bit格式它可以节省更多的帧缓存空间。使用24个bits通常就可以满足实时渲染的需要,但我们仍然有可能看到相邻色阶之间的差异带,但相比于16 bits的格式已经好很多了。
18.1.2 Z缓存
深度缓存的精度是非常重要的。试想你把一张纸放在一个书桌上,它们之间的深度差只有很小的差别。这样一来,深度缓存的精度将决定我们是否可以得到正确的排序结果。这种问题有时被称为深度冲突(z-fighting)。
深度缓存一般是24个bits。在正交视角下,深度值是和世界空间下的距离值成正比的,因此深度精度可以是均衡的。例如,我们说在世界空间下近远裁剪平面的距离是100米,而深度缓存使用16 bits存储格式,这就意味着任何相邻深度值之间的插值是一样的,也就是\(100m/2^{16} = 1.5mm\)。
然而,对于透视视角来说,情况就变得更加复杂了,因此深度精度分布并不是均匀的。在经过透视变换后,我们会得到一个点\(v = (v_x, v_y, v_z, v_w)\)。然后我们把它除以w分量,得到\((v_x/v_w, v_y/v_w. v_z/v_w, 1)\)。接着,深度分量v_z/v_w将从一个有效区间内(DirectX就是[0, 1])被映射到另一个区间\([0, 2^b-1]\)并储存到深度缓存中,这里的b就是bits的数量。然而,透视变换的特性导致物体越接近于观察者深度精度越高,尤其是在远裁剪平面和近裁剪平面之间距离很大时。回到我们之前的纸和桌子的例子,这种精度的变化意味着当观察者逐渐远离纸张时,可能深度精度不足以判断桌子和纸之间的排序关系,导致桌子反而显示在纸的前面。
18.1.3 单缓存、双缓冲和三重缓存
我们知道现代GPU通常会使用双缓存来防止用户看到图元真正的渲染过程。这一节将介绍更多的多重缓存概念。
首先考虑单缓存的情况。这种情况下这个缓存也必须是当前绘制给用户看的那个缓存。这样当渲染帧速率小于刷新速率的时候,就可能会发生神奇的情况,我们可能会看到图元逐渐挨个被绘制到屏幕上。即便渲染速率和刷新速率一致,也会出现问题,例如当我们需要清空缓存的时候,在电子束进行逐行扫描时我们会看到画面中只有部分内容发生了变化,噪声画面撕裂的现象。总之,出现问题的原因就是显示器还在扫描时,帧缓存里的内容却一直发生变化。
为了避免上述问题,我们通常会使用双缓存。此时,显示的画面其实是前置缓存(front buffer)里的数据,而幕后的后置缓存(back buffer )则包含了当前正在绘制的数据。然后,通常会在垂直回扫时显卡驱动会交换两个缓存中的数据来避免撕裂(参考前面的垂直同步)。需要注意的是,缓存的交换不必一定发生在垂直同步时,也可以是立即交换,这有利于最大化帧率。当交换完成后,当前的后置缓存就会作为渲染命令的接受者,而新的前置缓存就会显示给用户。对于那些全屏显示的程序来说,这个交换通常被实现成一个颜色缓存的换页技术(color buffer flipping),也被直接称为换页(page flipping)。这意味着,我们并不需要完全拷贝交换两个缓存,而只需要使用一个特殊的寄存器来存储当前前置缓存的地址即可。
我们可以为双缓存再增加一个缓存,即待定缓存(pending buffer),这种方法就被称为三重缓存。待定缓存和后置缓存类似,它们都是用于幕后渲染的,而且可以在显示前置缓存时被修改。这三个缓存会形成一个循环,如下图最后一行所示。这个图画得其实有点迷惑人,我们讲到的front、back、pending buffer其实是按它们的作用定义的,而并不是指某个固定的缓存,例如我们认为当前被显示的那个缓存就是前置缓存。而图里面标识的front、back、pending被固定成某个特定的缓存,这只是为了绘图方便而已。
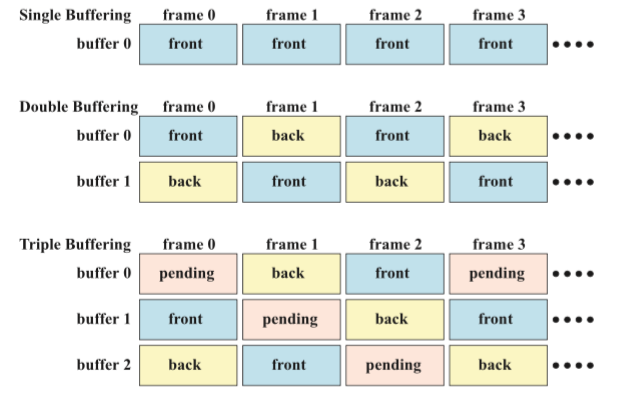
回到三重缓存上。三重缓存的一个主要优点在于当系统在等待垂直同步时,还可以访问待定缓存。而在双缓存情况下,换页操作可能会阻塞渲染流水线的工作,即换页操作必须要等待垂直同步信号才能执行。这是因为当前置缓存被显示给用户时,由于后置缓存已经包含了一个完整的图像所以也必须要保持不变(挨个来,已经有一帧还没有显示的图像了,下一帧就不能更新到后置缓存里了)。而三重缓存可以解决这样的问题(笔者注:但是其实也没有真正解决,如果待定缓存也满了,而又有新的帧来了呢?)。而三重缓存的缺点在于它提高了一整帧的延迟时间,例如会延迟用户输入的显示,由于多重缓存的存在用户的这些输入就被延迟了(其实不止三重缓存有这个问题,双重缓存也有,只要是有垂直同步就会有一定延迟)。因此,一些游戏宁愿关闭垂直同步而接受可能造成的画面撕裂来最小化这种延迟。
理论上,我们可以使用更多的缓存。如果帧率渲染速率是一直变化的,那么使用更多的缓存可以得到更好的平衡性而且可以得到更高的显示速率,但代价就是可能会造成更大的延迟。概括来说,多重缓存可以被认为是一个环形结构,我们有一个渲染指针和一个显示指针,每个指针会指向一个不同的缓存。当当先的渲染缓存完成计算时,渲染指针会指引着显示指针,移向下一个缓存。这里面唯一的规则就是,显示指针永远不应该和渲染指针指向同一个缓存。
一个相关的加速技术是SLI模式。早在1998年,3dfx使用SLI作为扫描线交错(scanline interleave)的缩写,SLI指的是两个显卡并行运算,一个显卡负责刷新奇数行,另一个负责偶数行。Nvidia后来收购了3dfx,它重新使用这个缩写作为另一个完全不同的方法的缩写,这就是可扩展的连接接口(scalable link interface),这种方法可以连接多个显卡进行计算。ATI/AMD把它称为CrossFire X。这种并行方法实际上是把屏幕分成了两个或更多的水平区域,每个显卡负责一个区域,或者每个显卡负责它自己的帧渲染,交替输出。这种模式通常可以让显卡加速当前帧的抗锯齿计算。最常用的就是让每个显卡渲染各自的帧,这被称为交替帧渲染(alternate frame rendering,AFR)。尽管这种方法听起来好像会提高延迟,但其实它几乎不会对延迟有任何影响。假设一个单独的GPU每秒渲染10帧。如果GPU是性能瓶颈的话,我们使用AFR技术来用两个GPU则可以达到20fps的速度,四个GPU就是40fps。每个GPU其实都使用了相同的时间来渲染帧画面,因此延迟不会发生什么变化。
18.1.4 立体和多视角图形
立体视觉的关键就是渲染两幅图像,一个是针对左眼,一个针对右眼,然后再使用某个技术来保证人眼可以体验到一种深度关系。这两张图像被称为立体像对(stereo pair)。一种常见的产生立体视觉的方法就是生成两张图像,一张是红色的,一张是绿色的(或是蓝绿色的),然后合成它们,再使用一个红绿眼睛来观看结果。
恩,这部分不是很感兴趣,所以先不写了。
18.1.5 缓存内存
假设我们有一个1280x1024大小的颜色缓存,并使用真彩进行存储,即每个通道8 bits。那么,我们需要1280x1024x4=5MB的空间来存储它。当使用双缓存技术时,这个值就变成了10MB。另外,我们假设深度缓存使用24 bits进行存储,模板缓存使用8 bits存储(通常会和深度缓存合起来得到一个32 bit的值),这样我们一共至少需要10+5=15MB的内存空间。需要注意的是,我们只需要一个深度缓存和一个模板缓存即可,而不需要对它们也使用多重缓存技术。当使用多重采样技术来提高画面质量时,这个内存值会变得更大。例如如果每个像素需要对应4个采样点,那么大部分缓存也都需要扩大4倍(太可怕)。